Introducción
En el vasto ecosistema de la investigación educativa, donde cada aula es un microcosmos de interacciones complejas, existe una necesidad imperiosa de identificar patrones, medir el impacto de las intervenciones y generar conocimientos que puedan ser generalizables a poblaciones más amplias. Es aquí donde la investigación cuantitativa se erige como un faro de la indagación sistemática, ofreciendo un lenguaje y un conjunto de herramientas para traducir los fenómenos educativos en variables medibles, analizar sus relaciones y probar teorías con rigor empírico. Este enfoque nos permite pasar de la anécdota a la evidencia, construyendo un conocimiento robusto que puede informar políticas y prácticas a gran escala.
Imaginemos que una nueva metodología de enseñanza promete revolucionar el aprendizaje de las ciencias. La pasión de sus defensores es palpable y los estudios de caso iniciales son inspiradores. Sin embargo, como académicos y futuros líderes educativos, nos enfrentamos a una pregunta crítica que trasciende el entusiasmo: ¿Funciona esta metodología de manera consistente en diferentes aulas, con diferentes estudiantes y bajo diferentes condiciones? Y más allá de si funciona, ¿cuánto mejor funciona en comparación con los métodos tradicionales y para quiénes es más efectiva? La investigación cuantitativa nos desafía a movernos más allá de la posibilidad para entrar en el reino de la probabilidad y la magnitud del efecto.
En esta lección, desmitificaremos el proceso de investigación cuantitativa, presentándolo no como una fría secuencia de pasos, sino como un ejercicio de lógica deductiva y diseño meticuloso. Comenzaremos estableciendo el fundamento teórico que da origen a las hipótesis. A continuación, exploraremos los diversos diseños de investigación como si fueran los planos de un arquitecto, cada uno con un propósito específico para establecer relaciones y causalidad. Navegaremos por las cruciales decisiones de muestreo y medición, para finalmente adentrarnos en la lógica del análisis estadístico, donde los datos se transforman en conclusiones significativas. Este recorrido está diseñado para equiparle con la competencia para construir, ejecutar y evaluar críticamente la investigación cuantitativa, un pilar indispensable en la formación de un investigador doctoral.
Desarrollo del tema
La lógica deductiva: del universo teórico al mundo empírico
El punto de partida del viaje cuantitativo es siempre una teoría. Una teoría es un mapa conceptual que explica cómo y por qué ciertos fenómenos están relacionados. A diferencia del enfoque cualitativo que busca construir teoría desde los datos (inductivo), el enfoque cuantitativo opera de manera deductiva: parte de una teoría general para derivar preguntas y, fundamentalmente, hipótesis específicas y comprobables. Una hipótesis no es una simple pregunta; es una afirmación predictiva sobre la relación entre dos o más variables que puede ser sometida a una prueba empírica.
Analogía: pensemos en el investigador cuantitativo como un arquitecto. El arquitecto no comienza a colocar ladrillos al azar. Primero, se basa en un cuerpo de conocimiento teórico (principios de la física, la ingeniería y la estética). A partir de esta teoría, diseña un plano detallado y preciso (el diseño de la investigación) que predice que, si las vigas (variables independientes) se colocan de una manera específica, el edificio (variable dependiente) se mantendrá firme y cumplirá su función. La construcción y prueba del edificio es el equivalente a la recolección y análisis de datos. El rigor está en la precisión del plano y en la fidelidad de la construcción a ese plano.
Este proceso exige la operacionalización de los constructos teóricos. Un constructo como la «motivación estudiantil» es abstracto. Para medirlo, debemos operacionalizarlo, es decir, traducirlo a indicadores observables y cuantificables. Podríamos definirlo como «el número de tareas opcionales completadas», «el tiempo dedicado al estudio fuera de clase» o las puntuaciones en una «escala de motivación intrínseca» validada. La calidad de una investigación cuantitativa depende críticamente de la validez de esta traducción del lenguaje teórico al lenguaje de las variables.
El plano de la inferencia: diseños de investigación
Un diseño de investigación es la estrategia o estructura que guía la recolección y análisis de datos para responder a la pregunta de investigación y probar las hipótesis. La elección del diseño es una de las decisiones más importantes, ya que determina el tipo de conclusiones que podemos extraer, especialmente en lo que respecta a la inferencia causal.
Diseños no experimentales
Incluyen los estudios descriptivos y correlacionales. Su objetivo es observar y describir las variables tal como existen naturalmente y explorar las relaciones entre ellas.
Caso de estudio: un investigador podría administrar una encuesta para medir los «niveles de agotamiento docente» y los «años de experiencia». Podría encontrar una correlación negativa (a más años de experiencia, menos agotamiento), pero sería un error concluir que la experiencia causa una reducción del agotamiento. Podrían existir otras variables (la «autoeficacia», por ejemplo) que expliquen esta relación. Los diseños correlacionales identifican relaciones, pero no pueden, por sí solos, establecer causalidad.
Diseños cuasi-experimentales
Se utilizan cuando el investigador introduce una intervención o tratamiento, pero no puede asignar aleatoriamente a los participantes a los grupos de tratamiento y control. Por ejemplo, se implementa un programa anti-bullying en un colegio (grupo de tratamiento) y se compara con otro colegio que no lo tiene (grupo de control). Aunque es más potente que un diseño correlacional, la falta de aleatorización introduce amenazas a la validez interna, ya que los dos colegios podrían haber sido diferentes desde el principio.
Diseños experimentales
Considerados el «estándar de oro» para establecer relaciones de causa y efecto. Su característica definitoria es la asignación aleatoria de los participantes a los diferentes grupos. Esta aleatorización asegura que, antes de la intervención, los grupos son estadísticamente equivalentes en todas las variables, conocidas o desconocidas. Por lo tanto, cualquier diferencia significativa observada en la variable dependiente después de la intervención puede atribuirse con mayor confianza a la variable independiente manipulada.
Tabla 1
Comparativa de diseños de investigación cuantitativa
| Diseño | Propósito principal | Característica clave | Fortaleza principal | Limitación principal |
|---|---|---|---|---|
| Correlacional | Describir la fuerza y dirección de la relación entre variables. | Medición de variables sin manipulación. | Permite estudiar un gran número de variables en entornos naturales. | No se puede inferir causalidad («correlación no implica causalidad»). |
| Cuasi-Experimental | Estimar el impacto causal de una intervención cuando la aleatorización no es posible. | Manipulación de la variable independiente; sin asignación aleatoria. | Mayor viabilidad y aplicabilidad en entornos educativos reales que los experimentos puros. | Amenazas a la validez interna debido a la falta de aleatorización (sesgo de selección). |
| Experimental | Probar hipótesis causales con el máximo control. | Manipulación de la variable independiente y asignación aleatoria a los grupos. | Alta validez interna; es el método más robusto para establecer causalidad. | Puede tener baja validez externa (artificialidad del entorno); a veces no es ético o factible. |
Nota. La elección del diseño implica un equilibrio entre el rigor (validez interna) y la relevancia en el mundo real (validez externa). Adaptado de «Experimental and Quasi-Experimental Designs for Generalized Causal Inference» por W. R. Shadish, T. D. Cook, y D. T. Campbell (2002).
De la multitud a la muestra: la lógica del muestreo
Rara vez es factible estudiar a toda una población de interés (ej. todos los estudiantes de secundaria de un país). Por ello, seleccionamos un subconjunto, una muestra. El objetivo del muestreo cuantitativo es obtener una muestra que sea representativa de la población, de modo que los hallazgos de la muestra puedan ser generalizados a esa población. El poder de la generalización depende enteramente de la calidad del método de muestreo.
Figura 1
El proceso de muestreo e inferencia
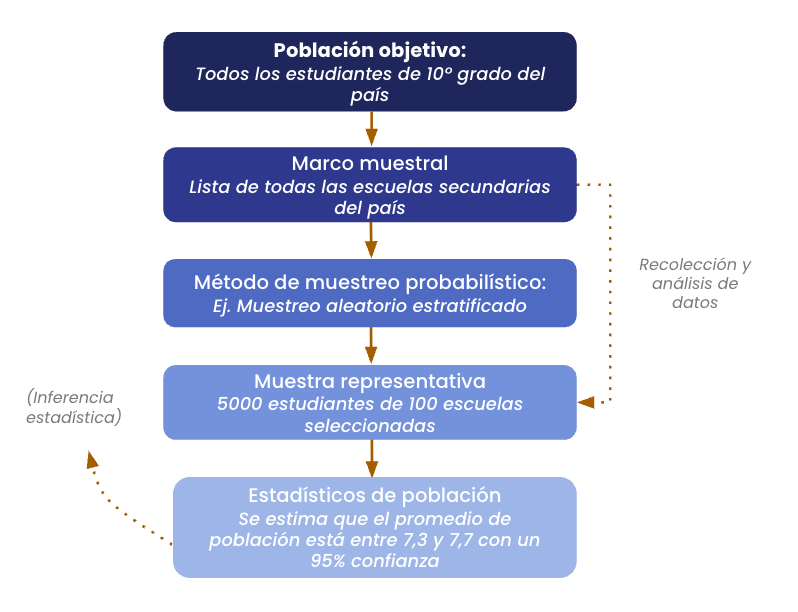
Nota. Este diagrama ilustra cómo, a partir de una población definida, se utiliza un marco muestral y un método probabilístico para seleccionar una muestra representativa. Los resultados obtenidos en la muestra (estadísticos) se utilizan para hacer inferencias o estimaciones sobre las características de la población (parámetros).
Existen dos grandes familias de técnicas de muestreo:
- Muestreo Probabilístico: cada miembro de la población tiene una probabilidad conocida y no nula de ser seleccionado. Estos métodos (muestreo aleatorio simple, estratificado, por conglomerados) son la base de la generalización estadística.
- Muestreo No Probabilístico: la selección se basa en el juicio del investigador o en la conveniencia (muestreo por conveniencia, por cuotas). Si bien son más prácticos, los resultados no pueden generalizarse estadísticamente a la población, lo que limita severamente el alcance de las conclusiones.
El desafío de la medición: confiabilidad y validez
Una vez seleccionado el diseño y la muestra, necesitamos instrumentos para medir nuestras variables. La calidad de estos instrumentos se juzga por dos criterios psicométricos esenciales:
- Confiabilidad: se refiere a la consistencia o estabilidad de una medida. Un instrumento es confiable si produce resultados similares bajo condiciones consistentes. Analogía: una cinta métrica es confiable. Si mides una mesa hoy y mañana, debería darte la misma medida. Si un test de ansiedad da puntuaciones muy diferentes a la misma persona en días consecutivos (sin razón aparente), su confiabilidad es baja.
- Validez: se refiere al grado en que un instrumento mide lo que se supone que debe medir. Es un juicio sobre la adecuación de las inferencias hechas a partir de las puntuaciones. Analogía: una báscula puede ser confiable (siempre te da el mismo peso), pero si está mal calibrada y siempre añade 2 kilos, no es válida porque no mide tu peso real. Un examen de matemáticas lleno de preguntas sobre historia podría ser confiable, pero no es una medida válida del conocimiento matemático.
La danza de los datos: del análisis a la interpretación
El análisis de datos cuantitativos transforma números brutos en conocimiento. Comienza con la estadística descriptiva, que resume y organiza los datos (medias, medianas, desviaciones estándar, frecuencias). Su propósito es «pintar un retrato» de la muestra.
El corazón del análisis, sin embargo, es la estadística inferencial. Su propósito es ir más allá de los datos de la muestra para hacer inferencias sobre la población y probar las hipótesis. El concepto central aquí es la significancia estadística (valor p). Un valor p bajo (típicamente < .05) sugiere que el resultado observado en la muestra (ej. la diferencia entre el grupo de tratamiento y el de control) es poco probable que se deba al mero azar del muestreo, lo que nos permite rechazar la hipótesis nula (la hipótesis de que no hay efecto o relación) y aceptar nuestra hipótesis de investigación. Sin embargo, como doctorandos, debemos ir más allá de una simple decisión de «significativo/no significativo» y prestar atención al tamaño del efecto, una medida que indica la magnitud o la importancia práctica de la relación o diferencia encontrada.
Conclusión
Hemos recorrido la arquitectura lógica de la investigación cuantitativa, desde la concepción de una teoría hasta la interpretación de los resultados estadísticos. Se ha visto que su proceso es una cadena de decisiones interconectadas y rigurosas: la formulación de hipótesis deductivas, la selección de un diseño que permita la inferencia causal, la obtención de una muestra representativa, la utilización de instrumentos válidos y confiables, y un análisis que distingue los patrones reales del ruido del azar. Este enfoque, lejos de ser una simple «numerología», es un poderoso método para generar conocimiento objetivo, replicable y generalizable.
El dominio de este proceso es esencial para el propósito de esta unidad, ya que nos proporciona un contrapunto claro y una base para el diálogo con el paradigma cualitativo. Comprender sus fortalezas (generalizabilidad, prueba de causalidad) y sus limitaciones (riesgo de simplificación excesiva, dificultad para captar el contexto) nos permite apreciar la necesidad de un pluralismo metodológico. Nos prepara para evaluar críticamente la investigación existente y, en última instancia, para diseñar estudios mixtos que integren lo mejor de ambos mundos.
Al concluir, te dejo con una pregunta para la reflexión continua: si la investigación cuantitativa se esfuerza por lograr la objetividad y la generalización a través del control y la estandarización, ¿cómo podemos, como investigadores en el campo profundamente humano de la educación, asegurar que nuestra búsqueda de patrones no nos haga perder de vista la individualidad y el contexto que definen las experiencias de aprendizaje?
Podcast de síntesis: la lección en audio
Como complemento, este recurso auditivo recapitula los conceptos fundamentales de la lección.
Bibliografía de referencia
- Creswell, J. W., & Creswell, J. D. (2018). Research design: Qualitative, quantitative, and mixed methods approaches (5th ed.). Sage publications.
- Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). Sage publications.
- Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Houghton Mifflin.
- Trochim, W. M. K., & Donnelly, J. P. (2008). The research methods knowledge base (3rd ed.). Cengage Learning.